
Công dụng:
3 function này được sử dụng để cập nhật dữ liệu từ các source => một cách đơn giản để crawl dữ liệu website (cập nhật giá sản phẩm của đối thủ cạnh tranh, thông tin thị trường, làm affiliate…)
Vấn đề:
Trong nhiều trường hợp, 3 hàm này trả lại thông báo: “#N/A Imported content is empty”. Vậy data source như thế nào thì phù hợp với 3 functions này:
Yêu cầu của data source:
+ Cả 3 function này đề đòi hỏi data source cung cấp dữ liệu tĩnh (static data) => để kiểm tra dữ liệu có phải là static data không, chúng ta dùng Chrome Developer tool (F12) => Ctrl + Shift + P => Disable javascript => rồi refresh lại webpage. Tất cả các dữ liệu vẫn còn hiển thị là static data & có thể sử dụng 3 function trên để lấy dữ liệu.
+ Với ImportXML: có thể lấy dữ liệu dạng XML hoặc biến thể (XHTML)
IMPORTXML(“URL”; “//ul[@class=’primary’]//li”)
Ví dụ:
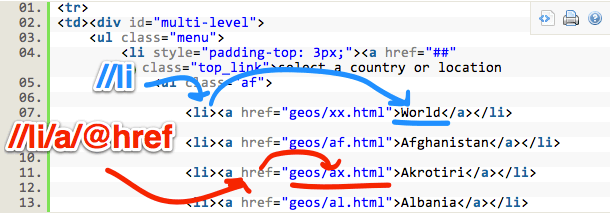
Để lấy được chữ “World” hay data nằm trong thẻ <a href>, ta có thể viết như sau:
ImportXML("URL","//ul[@class='
af']//li/a/@href")
Chú ý:
+ Đường dẫn Xpath dẫn đến giá trị cần lấy phải là duy nhất (unique) trong source code thì kết quả trả lại mới chính xác.
Nếu như đường dẫn trên là unique thì sẽ ra duy nhất một giá trị . Còn nếu giá trị trả lại gồm có nhiều kết quả thì chúng ta cần mở rộng đường dẫn Xpath ra lớp html bao ngoài đến khi nào đường dẫn là unique (div/div/p/ins/span).
+ ImportXML chỉ hỗ trợ Xpath 1.0 (cách copy Xpath từ browser console F12 không sử dụng được).
+ Sourcecode web thường được tối ưu về dạng minified => Công cụ để beatify html online: https://www.freeformatter.com/html-formatter.html
Ref:
+ https://zoomspring.com/blog/learn-importxml-tutorial/
+ https://www.distilled.net/blog/distilled/guide-to-google-docs-importxml/
+ Hàm ImportData: có thể lấy dữ liệu dạng csv hoặc tsv (không phụ thuộc vào đuôi của file dữ liệu)
ARRAY_CONSTRAIN(IMPORTDATA(“URL”); 8000; 20)
+ ImportFeed: có thể lấy dữ liệu dạng ATOM/RSS
+ ImportHTML: có thể lấy dữ liệu HTML dạng bảng (table) hoặc dạng danh mục (list)
IMPORTHTML(“URL”; “Query”; ROW(A1)-1)
If kết quả của function này không phải là #N/A thì có thể sử dụng function kết hợp với Xpath để lấy kết quả mong muốn.
+ URL: bao gồm cả protocol (http/https) và nằm trong ” “
+ Query: chọn “table” hoặc “list” tùy theo định dạng data cần lần được đặt trong cấu trúc table hay list
+ Index: xác định thứ tự của “Table” hoặc “List” trong webpage đó. Index bắt đầu từ 1